Can machine learning speed up UX research analysis?
A new experiment from the Evolve Team

Human + AI is a powerful combo
In the future, I see operators guiding groups of algorithms: it will be a time when machines will be able to generate their own knowledge based on human-produced frameworks ... Human plus machine means finding a better way to combine better interfaces and better processes
-- Gary Kasparov (Chess Grandmaster)
There is a lot of value in using intelligent systems to improve the quality of our work. For text analysis our best AI algorithms are still lackluster (in spite of what some headlines may tell you about work like GPT-3). Perhaps one day an algorithm could take all of your qualitative research notes and summarise them for you. For now we have to rely on other approaches.
At Evolve we've been looking at using Machine Learning to speed up the process of analysing UX research. Our latest approach is to use Natural Language Processing to kickstart the research process rather than to try to replace it.
We've experimented with a lot of approaches including complex algorithms involving neural networks. The complex approaches didn't generate particularly impressive results and we've found that a simple algorithm actually worked best.
Our idea

Our approach is simple:
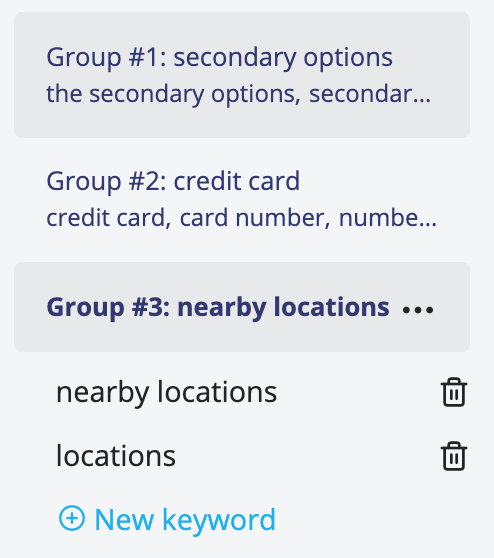
- Use Natural Language Processing techniques to identify the most important keywords
- Create a group of keywords that are related
- Show all of the research notes that contain one of those keywords
- Allow researchers to modify the keyword groups or create their own
- The researcher can select groups of notes that contain that keyword and add them to a research finding
The algorithm isn't perfect. But given that the algorithm can analyse a typical UX research project in a couple of seconds its results are generally useful.
The most useful aspect of this approach is that it can help fast-track the analysis process. We want users to be actively engaged in the research process rather than relying on an algorithm to analyse their research for them.
If the algorithm adds incorrect keywords to a group - remove them. If it misses an important keyword - add it. If there is a topic that you feel isn't covered - create one.
From there it's about finding patterns and interesting observations in the data. With this approach it should be easier to identify research findings by only looking at a subset of the data.

Is this approach effective?
At this stage we're looking for feedback on whether or not this is useful in analysing the UX research process. The Evolve UX Research app has a completely free plan and our paid plan is free while we're in beta. If you have any feedback on this approach we'd love to hear it.
Back to blog